
Будущее наступило: уже сейчас генеративные нейросети помогают писать код, рисовать картины по текстовому запросу, без лишних споров берут на себя рутинные и скучные задачи специалистов из разных сфер. Причем дальше — больше, потому что технологии быстро развиваются, раздвигая границы возможного. В этих условиях российским компаниям во многом приходится балансировать, чтобы успевать за трендами и «не сваливаться в прошлое» в условиях новых вызовов.
Меня зовут Николай Карлов. Я директор инновационных проектов в VK Tech. В этой статье я расскажу о технологиях и подходах, которые могут оказаться самыми полезными в 2024 году, и покажу, как их можно применять. Поговорим про вектора, эмбеддинги и Feature Stores, как разделить Compute и Storage, про транзакционно-аналитическую обработку данных и при чем тут Tarantool.
Статья подготовлена по мотивам доклада на VK Data Meetup «Что предстоит делать с данными в 2024 году?».
Глава 1. AI & ML
Любой элемент контента (введенный текст, фрагмент речи, продуктовое предложение, видео и не только) с помощью нейросетей можно представить в виде вектора, то есть в виде массива чисел от 0 до 1. Вектор может иметь более тысячи компонентов, а в случае сложных, например генеративных, моделей счет подобных компонентов может идти уже на миллионы. При этом в реальных проектах в базе может находиться 10 млн и даже 100 млн векторов.
Каждый такой вектор называется эмбеддингом. И создаются эмбеддинги для абсолютно всего в проекте.
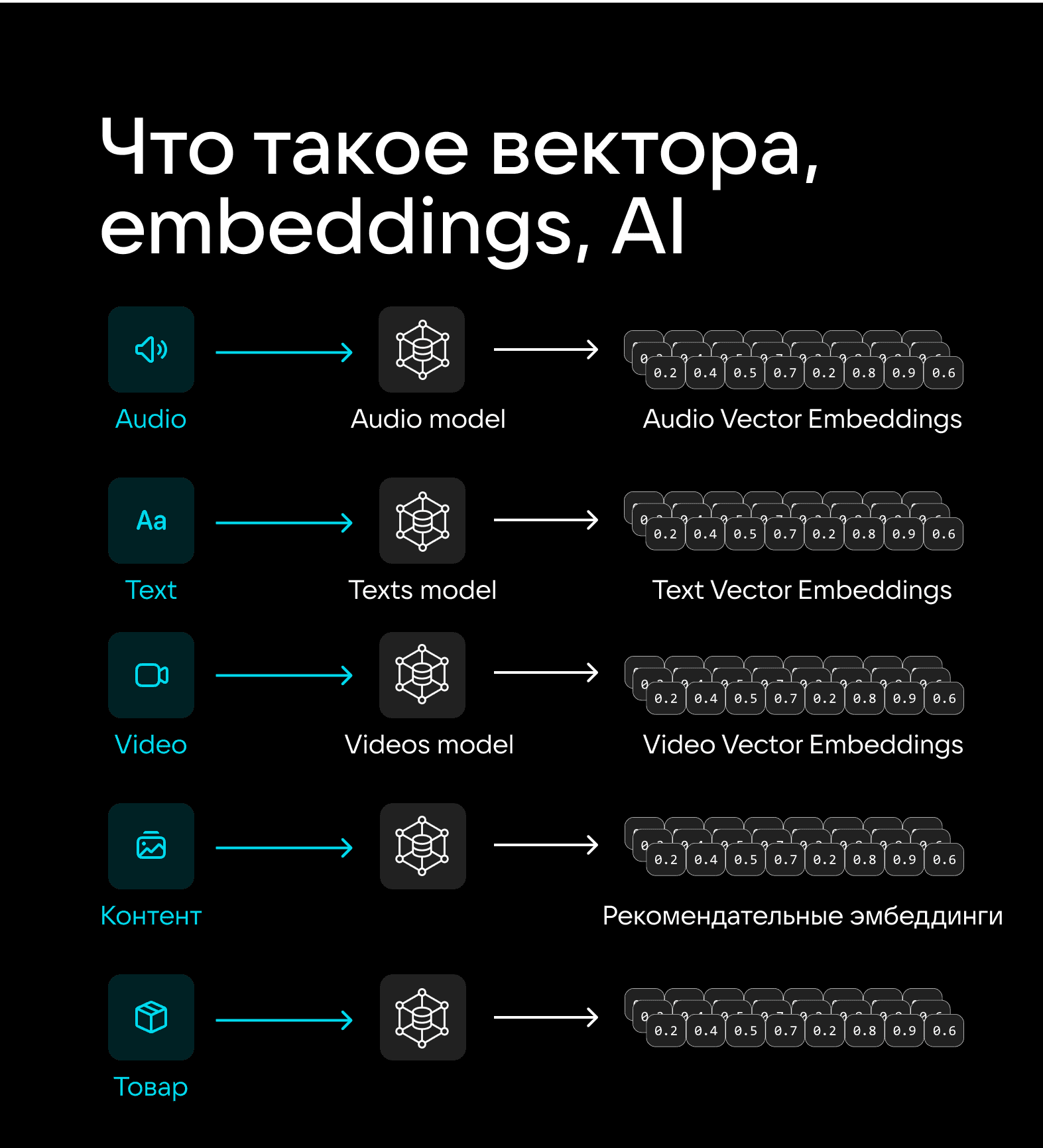
Необходимость преобразования контента в эмбеддинги связана с тем, что для «машины» все картинки, буквы, символы — всего лишь непонятные «абстрактные объекты». То есть создание эмбеддинга можно сравнить с чем-то вроде перевода с «человеческого на машинный». Итого: такое преобразование — must have для любых операций, в которых алгоритмы должны распознавать содержимое контента. Например, без этого невозможны ранжирование контента, работа рекомендательных систем, скоринг, проверка на фрод и другие операции с исходными данными.
Что такое Feature Store и при чем здесь вектора
Стандартно данные о пользователе делят на две составляющие: профиль и поведение.
К профилю относится информация, которая не изменяется или изменяется минимально и редко: например, пол, возраст, долгосрочные интересы, активный тарифный план, средний чек в месяц и другие.
К метрикам поведения относят данные о действиях пользователя: что он посмотрел, купил, лайкнул, свайпнул и так далее.
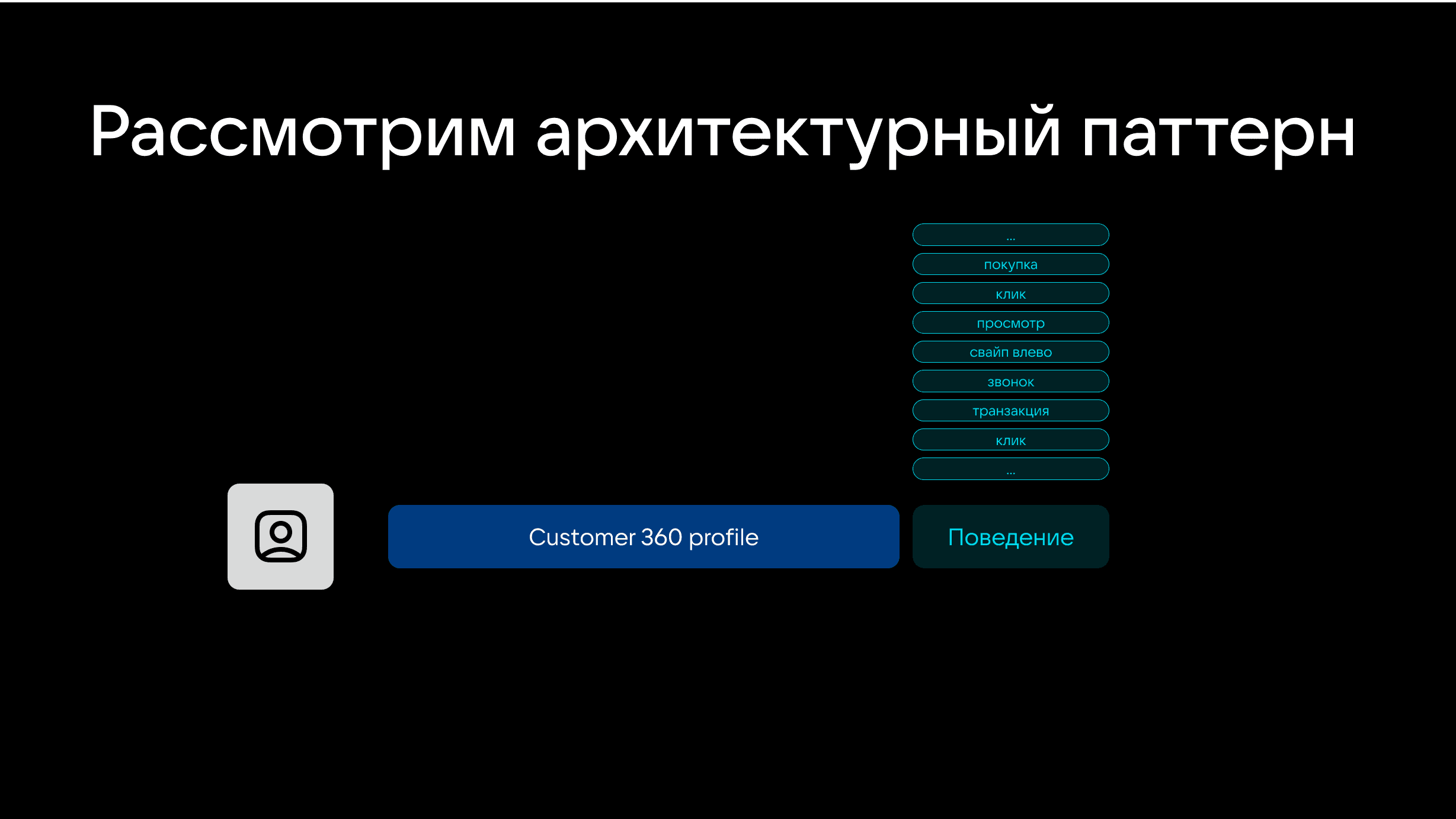
При работе с данными дата-сайентисты могут рассматривать каждый элемент полезной информации в качестве фичи, а фичи использовать для рекомендательных моделей, ранжирования, анализа и других задач.
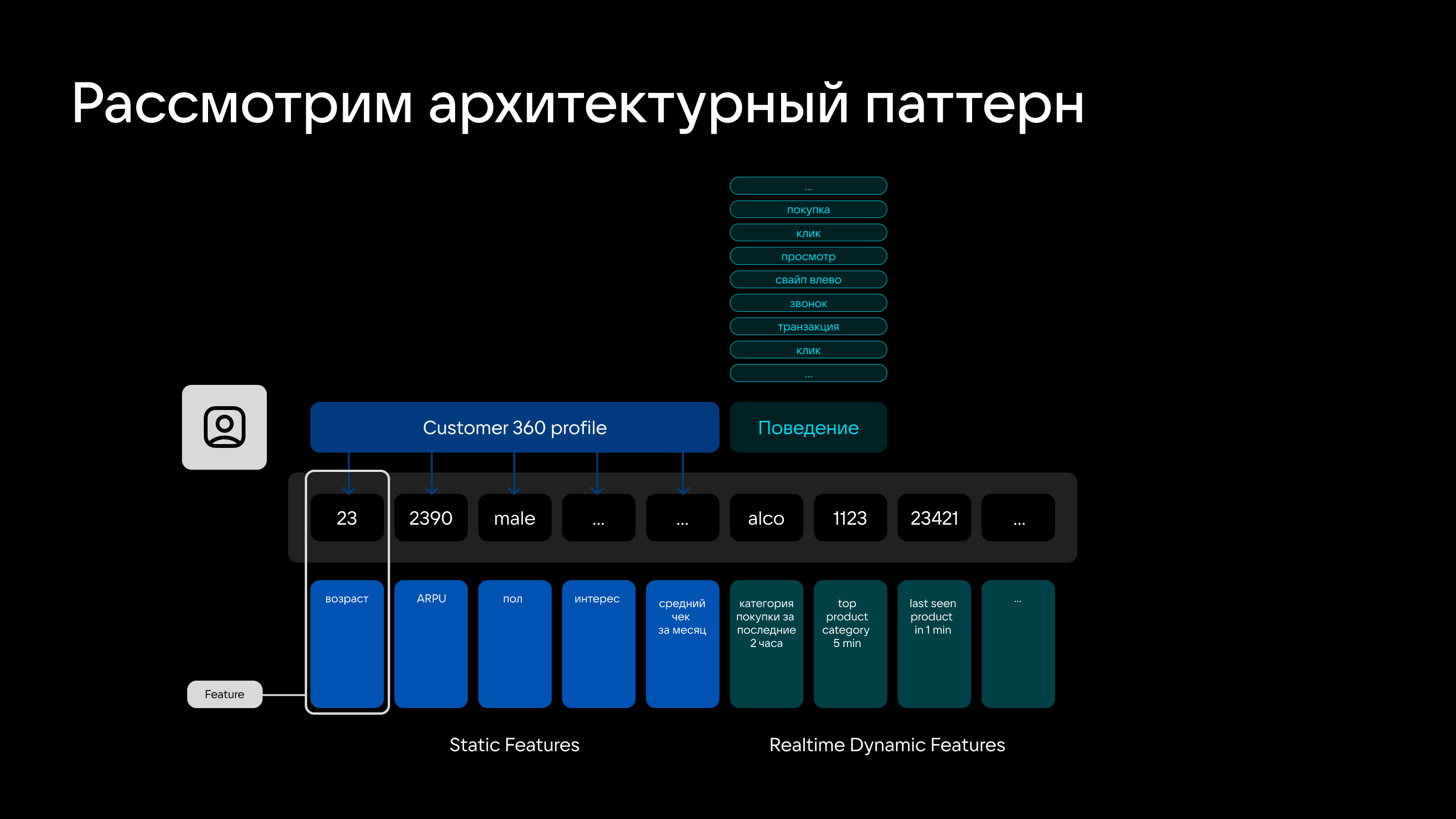
В зависимости от типа данных фичи можно разделить на:
- статические — например, которые описывают пол, возраст;
- динамические — данные, которые меняются часто или даже в реальном времени. Комбинация фичей формирует фича-сет, а система для хранения и создания фичей называется фича-стором (Feature Store).

Почему это важно?
Есть модели, которые умеют создать эмбеддинги и, соответственно, фичи в real-time. Это свойство можно использовать в том числе для создания поисковых векторов (Search Vector) и сравнения данных на лету.
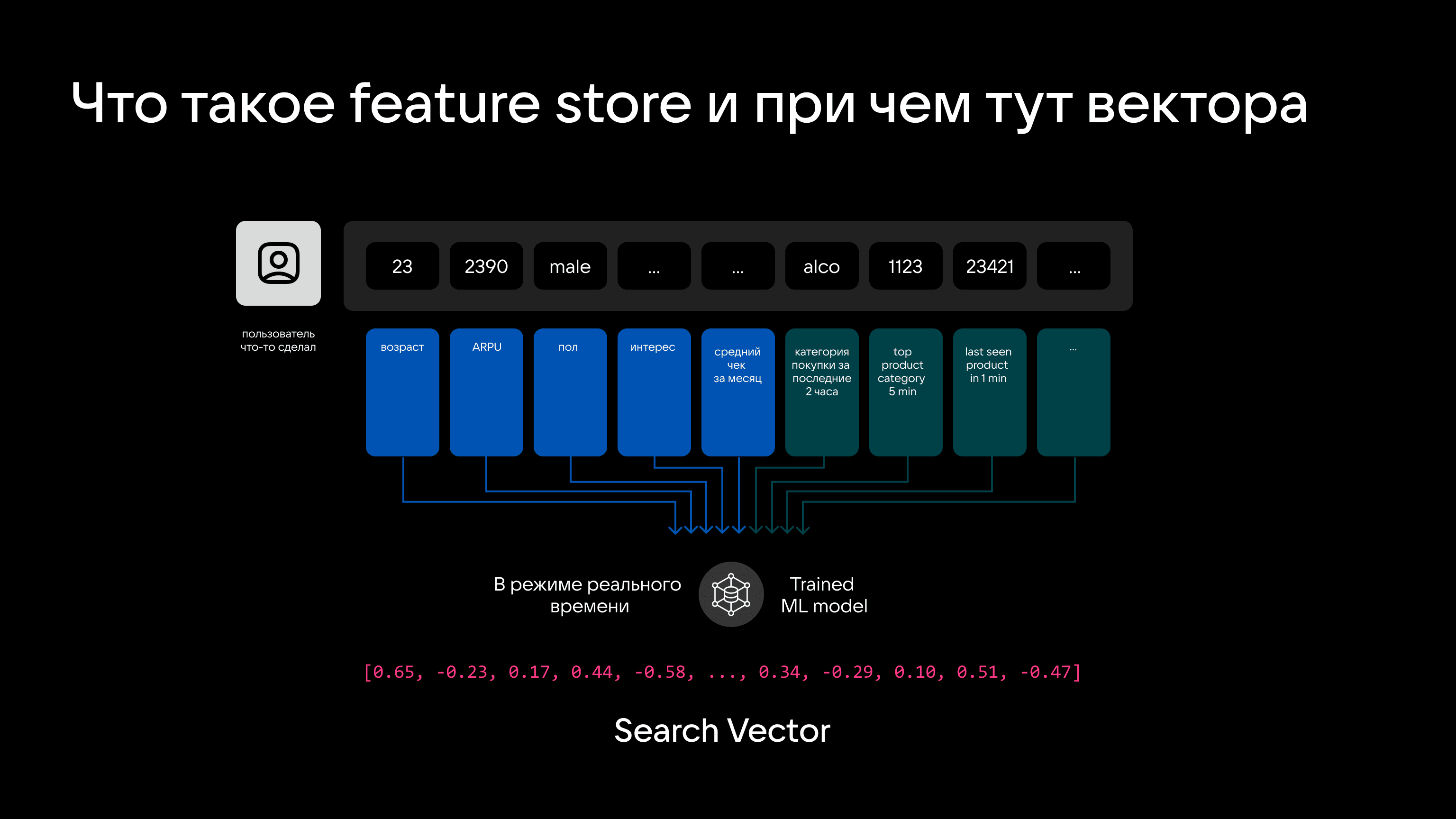
Таким образом, нейросети и векторные движки только в рамках этого кейса решают сразу три задачи:
- создание фича-стора с набором эмбеддингов;
- создание при обращении пользователя эмбеддинга в реальном времени на основе актуальных данных;
- поиск ближайших эмбеддингов, соответствующих продуктам, документам, офферам или другому типу контента.
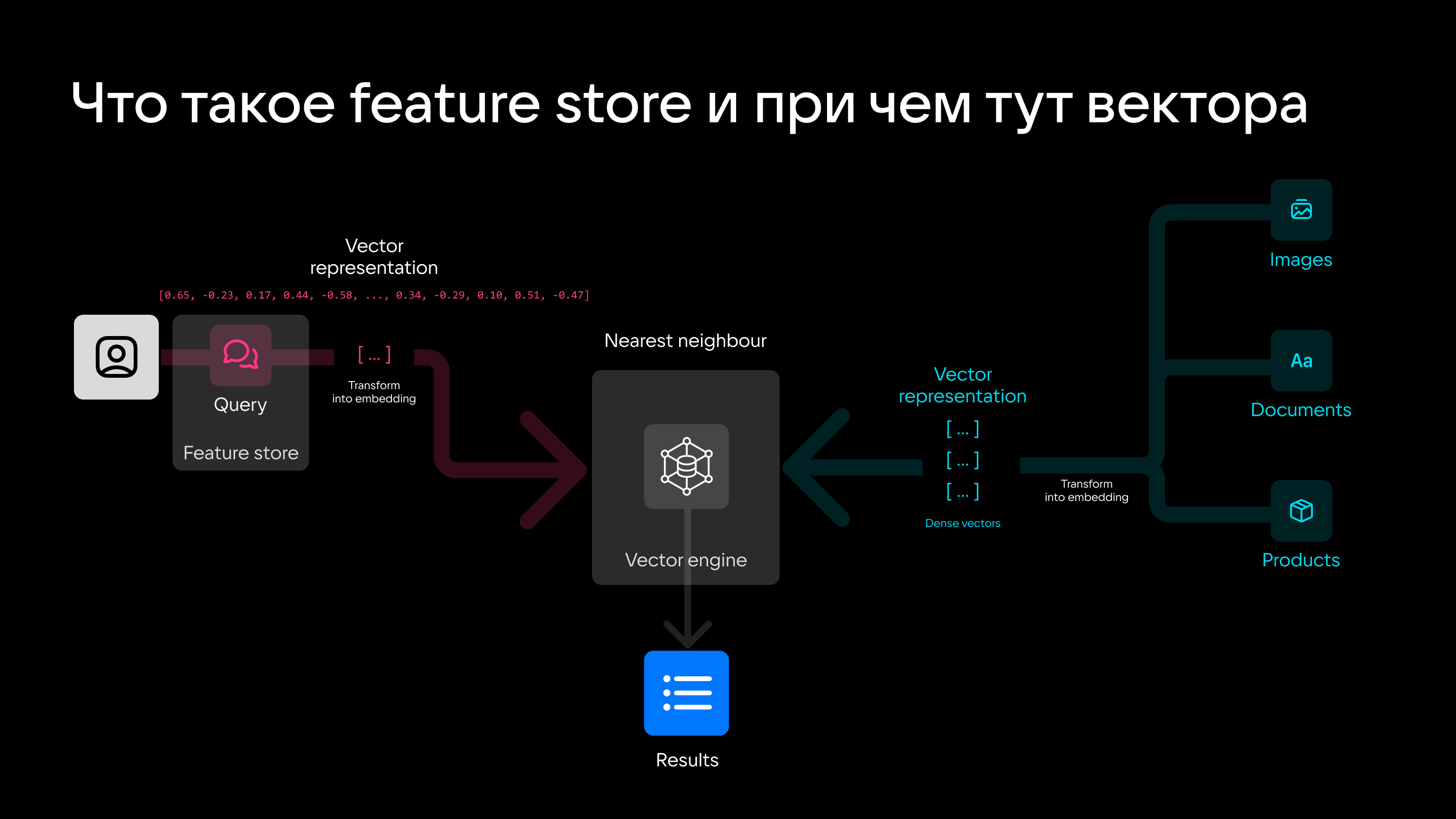
То есть, вооружившись таким стеком технологий, вполне можно реализовать сценарий, при котором покупатель заходит в интернет-магазин и получает наиболее релевантные предложения на основе истории покупок, предпочтений, пола и других факторов.
Благодаря такой «сверхспособности» векторные движки однозначно являются трендом 2024 года.
Глава 2. HTAP & Columnar In-memory
Всё большую актуальность получают задачи, связанные с поиском похожих векторов. Но в разных кейсах механизм очевидно должен работать по-разному: например, в системах видеонаблюдения база данных векторов должна быстро перестраиваться и осуществлять поиск мгновенно, а в системах оплаты с помощью лица это не нужно — загруженные биометрические данные фактически статичны по отношению к поисковым запросам (логично: лицо и отпечатки не меняются каждый день).
Поэтому одни системы ориентированы на работу с историческими данными, а другие — на обработку данных «здесь и сейчас». Исходя из этого, обычно для разных профилей нагрузок используют разные инструменты — например, для OLAP-запросов (Online Analytical Processing, оперативная обработка данных) это Hadoop, Greenplum, ClickHouse, S3-хранилища. Для OLTP (Online Transaction Processing, обработка транзакций в реальном времени) — Hazelcast, Redis, Tarantool.
Но в условиях не «идеального», а реального мира задачи OLAP- и OLTP-обработки нередко пересекаются — например, когда система аналитики должна уметь учитывать мгновенное изменение данных или, наоборот, когда транзакционная система должна выполнять аналитические запросы, требующие обработки исторических данных.
Таким образом, есть большой пул сложных гибридных транзакционно-аналитических запросов, которые не вписываются ни в транзакционный, ни в аналитический профиль и требуют гибридной транзакционно-аналитической обработки данных (HTAP, Hybrid Transaction / Analytical Processing). Чаще всего такие запросы встречаются в задачах скоринга, антифрода, ML, аналитики действий пользователя, транзакционных операциях в реальном времени и не только.
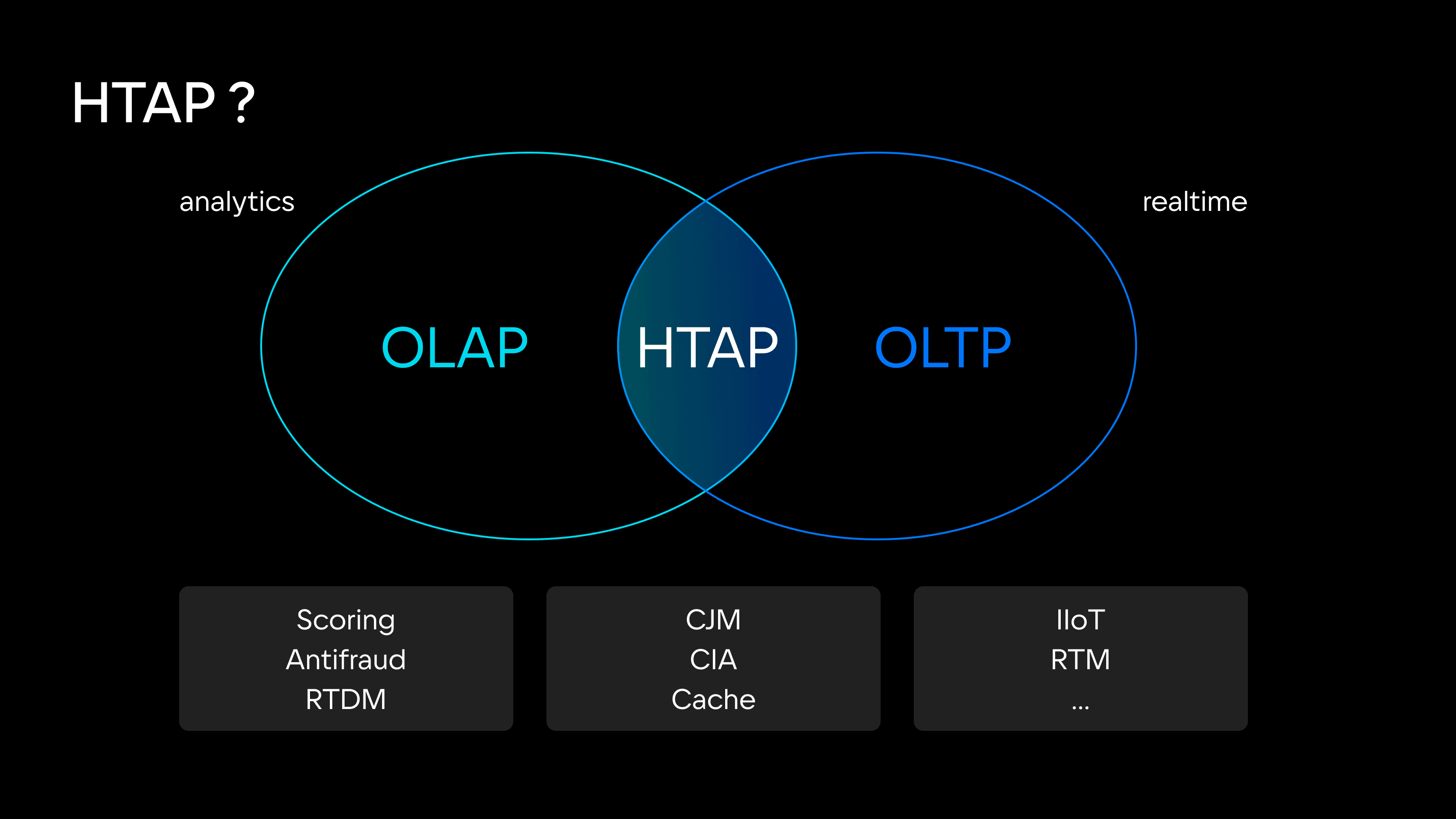
Причем постепенно таких запросов становится заметно больше. Игнорировать этот факт сложно и даже глупо, поэтому HTAP-решения, которые объединяют транзакционную и аналитическую обработку данных в одной системе, заслуженно являются трендом 2024 года и, вероятно, следующих лет.
Как правило, это In-memory БД, которые используют колоночные и строчные движки в сочетании с колоночным транспортом — такая архитектура позволяет использовать все преимущества колоночного представления, но не копировать данные, а интерпретировать их внутри приложений, что заметно повышает производительность баз данных.
Пример HTAP-решения — Tarantool Column Store, In-memory-колоночная СУБД для транзакционно-аналитической обработки данных в реальном времени. Продукт способен на массовую параллельную обработку больших объемов данных, горизонтально масштабируется за счет шардирования. Tarantool Column Store находит свое применение в кейсах формирования отчетности компании в реальном времени, расчетов агрегатов для антифрод-систем в финансовых организациях, повышения производительности систем выдачи кредитов.
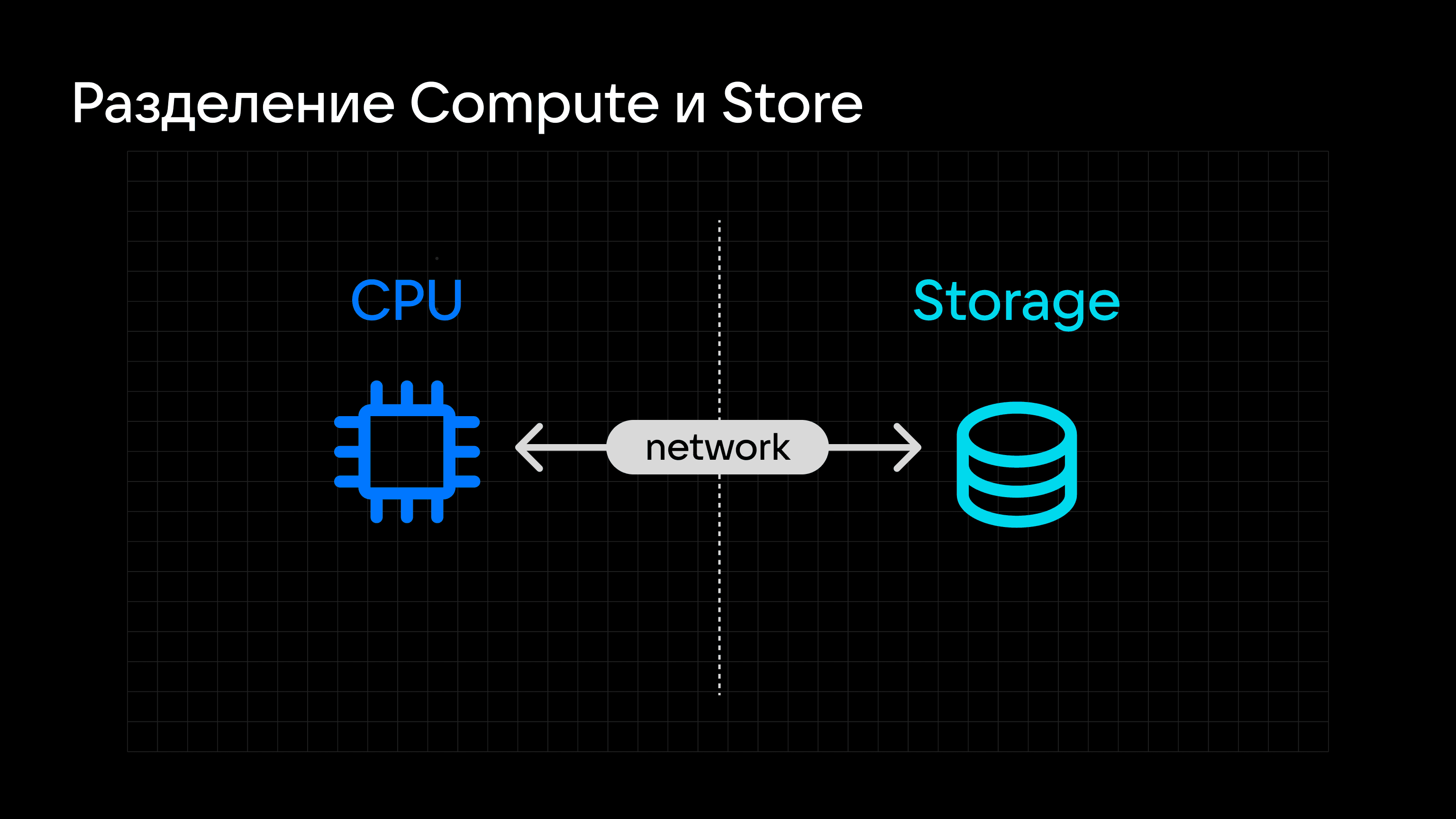
Глава 3. Разделение Compute- и Storage-слоев
Удивительно, но востребованные решения иногда возникают даже в там, где, казалось бы, уже все изобретено.
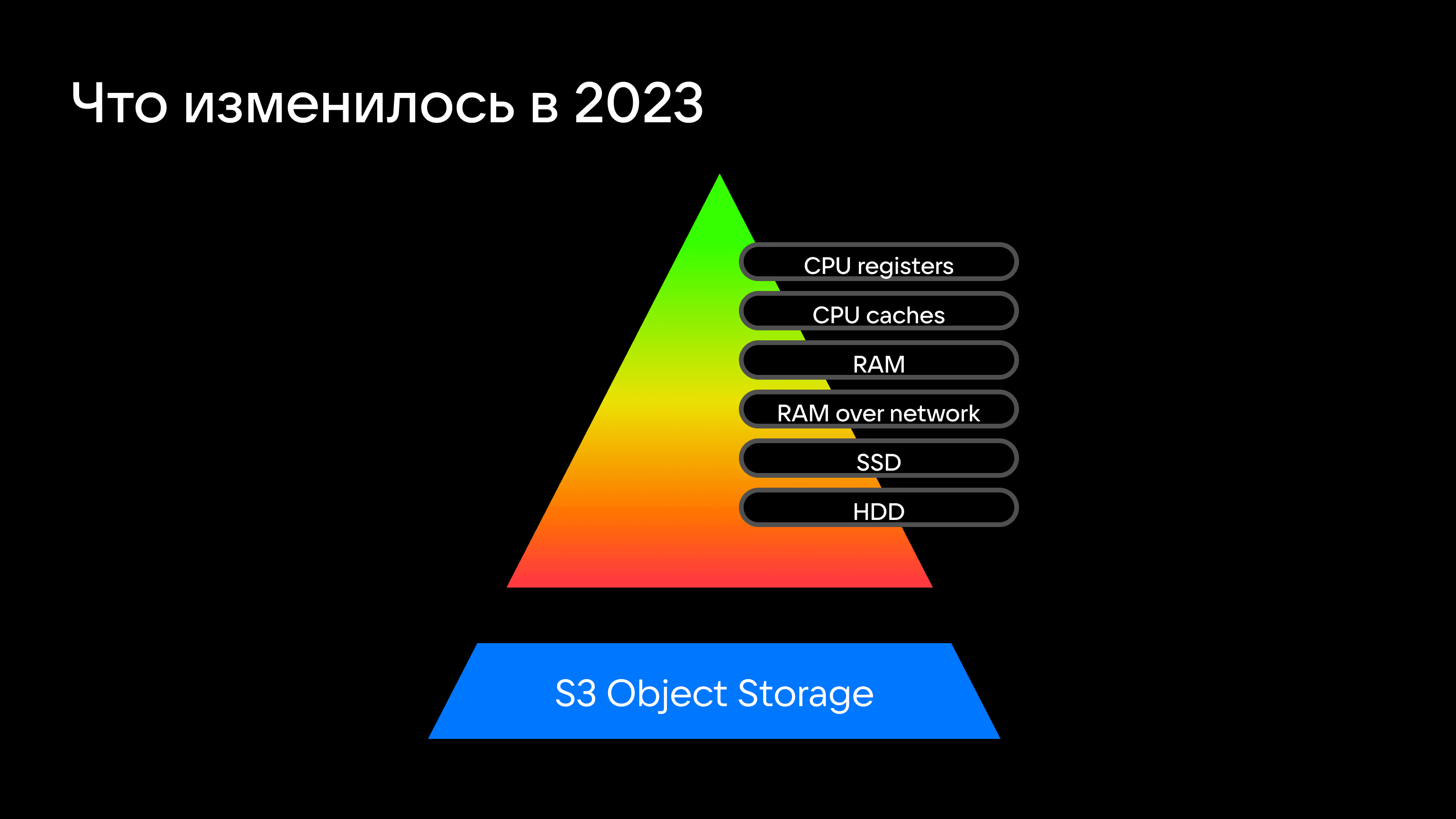
Традиционно скорости работы с данными зависят от носителя, на которых они хранятся. Тут все очевидно: регистры процессора на порядки быстрее доступа к памяти, а скорость доступа к оперативной памяти соседнего в стойке сервера быстрее, чем к локальному HDD-носителю. Что, кстати, лежит в основе систем класса In Memory Data Grid, к которым относится Tarantool.

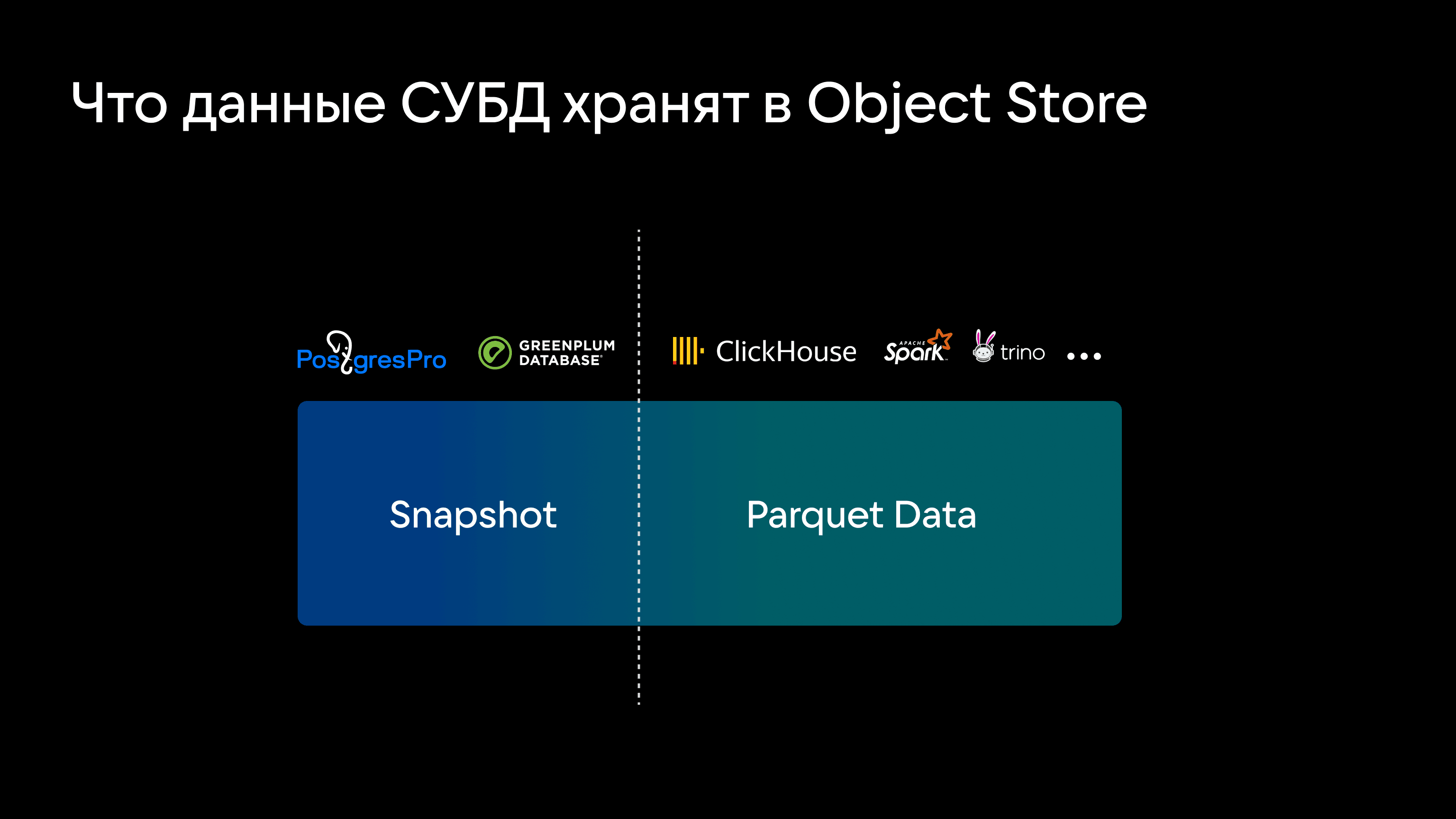
Но выбор типов хранилищ для сбора и обработки аналитических данных шире, чем все думают. Так, немецкий ученый Томас Нейман провел исследование Exploiting Cloud Object Storage for High-Performance Analytics, в рамках которого хотел проверить, подходят ли объектные хранилища (S3) для задач быстрой аналитики. Мотив такого интереса простой: стоимость терабайта хранения в S3-хранилище значительно ниже, чем терабайта хранения на физическом сервере или даже виртуальной машине.
Для проведения эксперимента был разработан движок, который эмулировал работу с файловой системой для базы данных, но делал это с объектным хранилищем — с кэшированием и другими алгоритмическими манипуляциями. Исследование показало, что аналитические СУБД с данными в S3 работают не хуже, чем с локальным диском, а иногда и лучше. Причем бутылочным горлышком в большей степени являются ограничения со стороны вычислительных ресурсов (Compute), нежели хранилища (Storage), что повышает актуальность разделения Compute- и Storage-слоев.
Больше пищи для размышлений дало и исследование Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases, которое показало, что S3 можно использовать не только для хранения аналитических данных, но и для работы в паре с обычными БД — например, Postgres вполне может хранить в S3 логи, снапшоты и не только. Естественно, чтобы исключить необходимость постоянного обращения в S3, нужна система кэширования для разделения Compute и Storage. То есть S3 решает задачи хранения, а вычисления вынесены в Compute-узлы, которые можно независимо добавлять.
По результатам исследования, при равном количестве вычислений конфигурация с S3 «под капотом» работает в три раза быстрее классической реализации. Причем в ходе эксперимента эмулировалась работа сложной транзакционной системы — интернет-игры. Это говорит о том, что разделение Compute и Storage хорошо влияет на обработку как аналитических, так и OLTP-запросов. При этом сохраняются и привычные преимущества S3-хранилищ — гибкое масштабирование и условно неограниченная вместительность.
Итого: S3-хранилища вполне можно рассматривать в качестве основного компонента пирамиды распределения скоростей доступа к данным. Но лучше без четкого определения их места в иерархии, потому что параметры S3-хранилищ в таком кейсе не постоянны, а зависят от сценариев использования и того, разделены ли слои хранения и вычисления.
Важен еще один момент. В контексте разделения Compute и Storage важно найти замену привычным решениям вроде Cloudera и Hadoop. Причем запросы у компаний обычно совсем не скромные (мягко говоря): нужно сочетать бесконечное и дешевое хранилище, масштабируемые распределенные вычисления, совместимость с другими инструментами в стеке и поддержку вендора.
Вместе с тем — и здесь объектные хранилища могут быть полезны — их можно применять как для хранения снапшотов и журналов транзакций, так и для сжатых аналитических данных в исходном виде. То есть базы данных могут работать поверх S3 так же, как и поверх HDFS в стандартной реализации.
Глава 4. Пример работы с трендовыми технологиями в рамках одного кейса
Итого, в топ-рейтинг трендов 2024 года вполне заслуженно входят:
- графовые СУБД;
- векторные СУБД;
- Feature Store;
- разделение Compute и Storage;
- колоночные In-Memory БД для гибридной транзакционно-аналитической обработки.
Учитывая эти тренды, Tarantool развивает продукты Tarantool Column Store, In-memory-колоночную СУБД, и Tarantool Graph DB, графово-векторную базу данных для анализа связей между объектами в реальном времени.
Рассмотрим на примере построения антифрод-системы, как можно применять трендовые подходы и технологии в реальных задачах.
Антифрод — автоматизированная система безопасности для оценки банковских или онлайн-операций по определенным критериям с целью предотвращения мошеннических транзакций.
Антифрод срабатывает тогда, когда система начинает обнаруживать признаки подозрительной активности — например, когда с карты несколько раз подряд оплачивают покупки по 1000 рублей в обход защите по пин-коду, или когда интенсивность транзакций выше обычного — например, когда с карты начинают в «хаотичном порядке» делать покупки и денежные переводы. Как правило, такая подозрительная активность заканчивается блокировкой карты или дополнительными проверками для подтверждения операций.
В первую очередь такой антифрод полезен пользователю: чем раньше будет обнаружен и заблокирован слив денег, тем меньше будет ущерб. Но от банка создание такой системы требует сложной технической реализации.
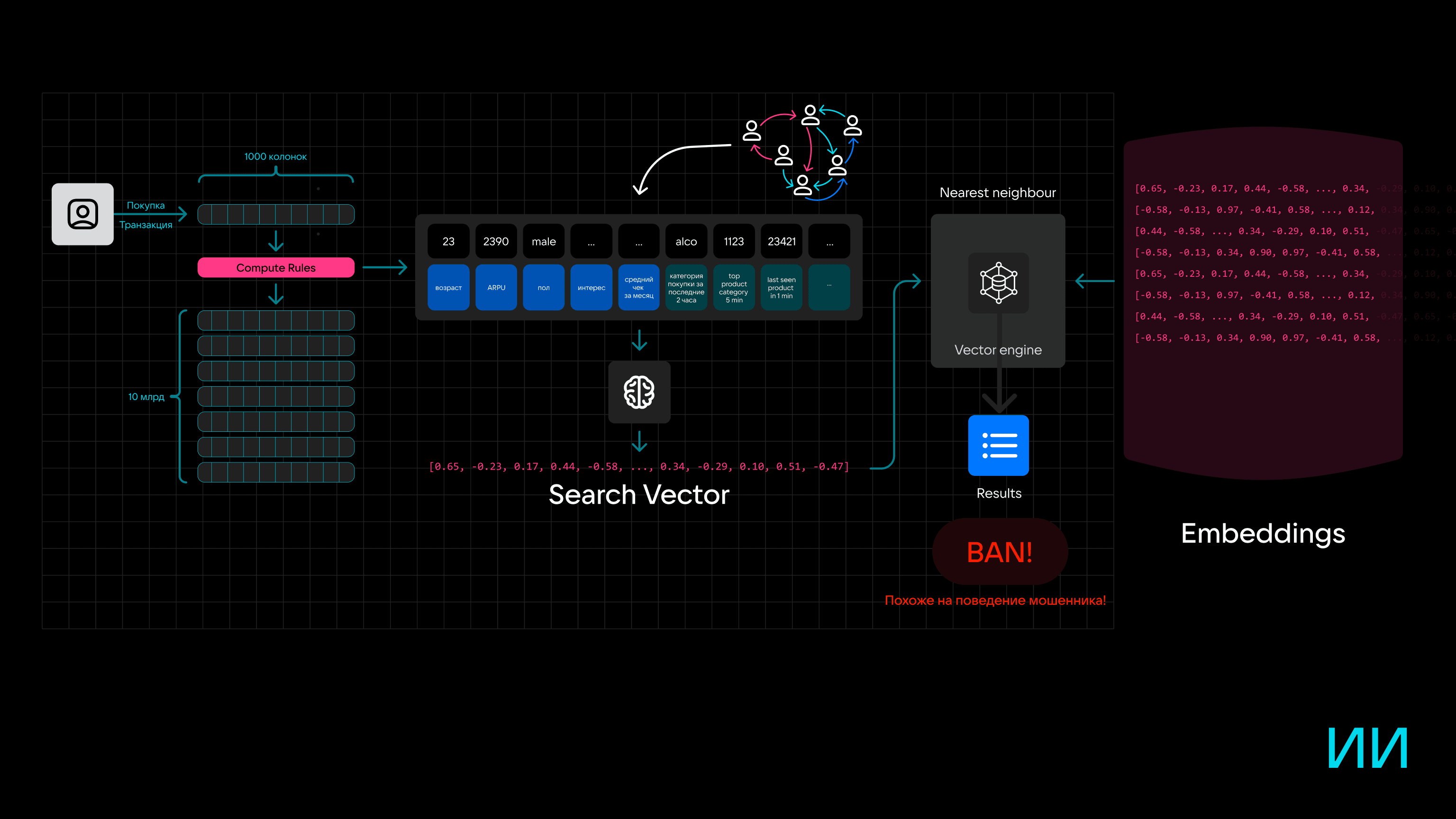
Так, каждая покупка условно представляет собой запись на 20–30 полей. Но на самом деле в базу данных записываются тысячи колонок: информация о покупке дополняется риск-векторами, статистической информацией о пользователе, словарями, аналитическими данными и не только. После создания запись передается в консолидированное хранилище.

Но между созданием записи и ее попаданием в хранилище есть этап вычислений (Compute).
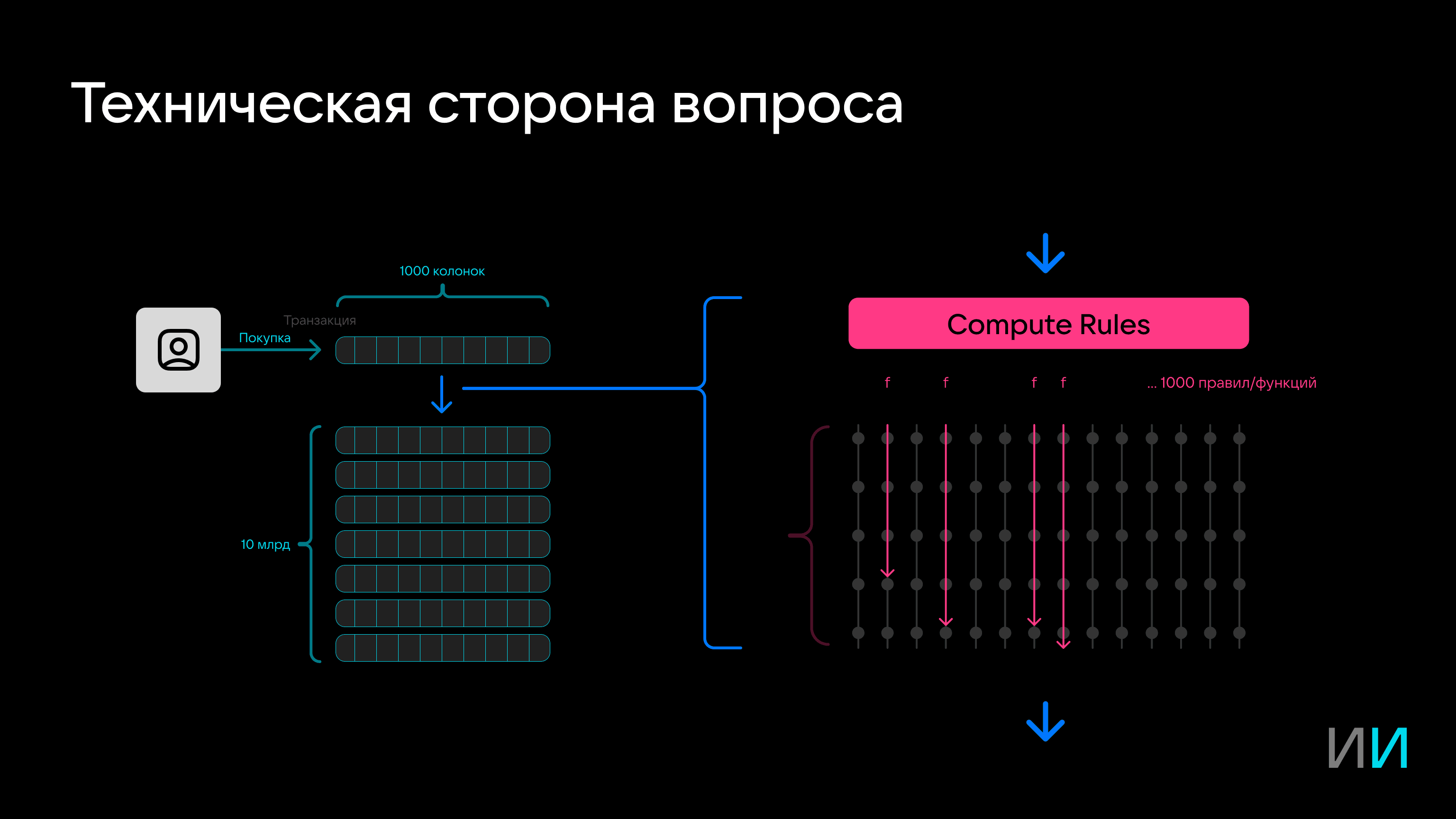
Здесь запись проверяется на соответствие правилам и счетчикам — например, проверяется, что доля покупок в одном месте не превышает установленный порог, или наоборот, для продавца — что покупки совершает не один клиент.
Таких правил могут быть тысячи. Причем сложность и тип вычислений могут отличаться — например, от расчета суммы до определения среднеквадратичных отклонений. Фокус в том, что вычисления во время вставки не менее 1000 агрегирующих функций, которые анализируют историю, как правило, надо успеть выполнить приблизительно за 10 миллисекунд.
Под такие задачи по разным причинам в чистом виде не подходят ни транзакционная (OLTP), ни аналитическая (OLAP) системы. В том числе из-за того, что таких запросов может быть 10 тысяч в секунду.
Еще один вариант — агрегирование на лету с помощью Event Sourcing (CEP), когда события приходят через условную Kafka или очередь. В таком случае можно быстро обновлять счетчики и не надо «смотреть в прошлое».
Но и использование Event Sourcing возможно не всегда. Почему? Объясню на примере.
Даже простое определение доли операций с конкретной суммой у одного пользователя за 10 дней требует большого объема вычислений и ресурсов. Особенно если пользователей и вариантов суммы много.
Так, для 20 млн пользователей и 1000 вариантов суммы (вариантов много, потому что сумма в чеке практически всегда отличается и надо учесть максимум потенциальных значений) расчет будет следующим:
20 млн пользователей х 1000 вариантов Amount = 20 млрд записей
20 млрд записей занимает около 150 ГБ, и это только для одного счетчика (немало, да?). При большем количестве счетчиков можно получить комбинаторный взрыв. Причем вычисления могут быть более сложными, с большим количеством зависимостей — «бум» будет неизбежен.
Для таких задач больше подходят HTAP-решения, ориентированные именно на аналитическую обработку в реальном времени.
В расширенном виде этап Compute Rules можно представить в виде фича-стора, а каждый элемент данных — отдельной фичей.
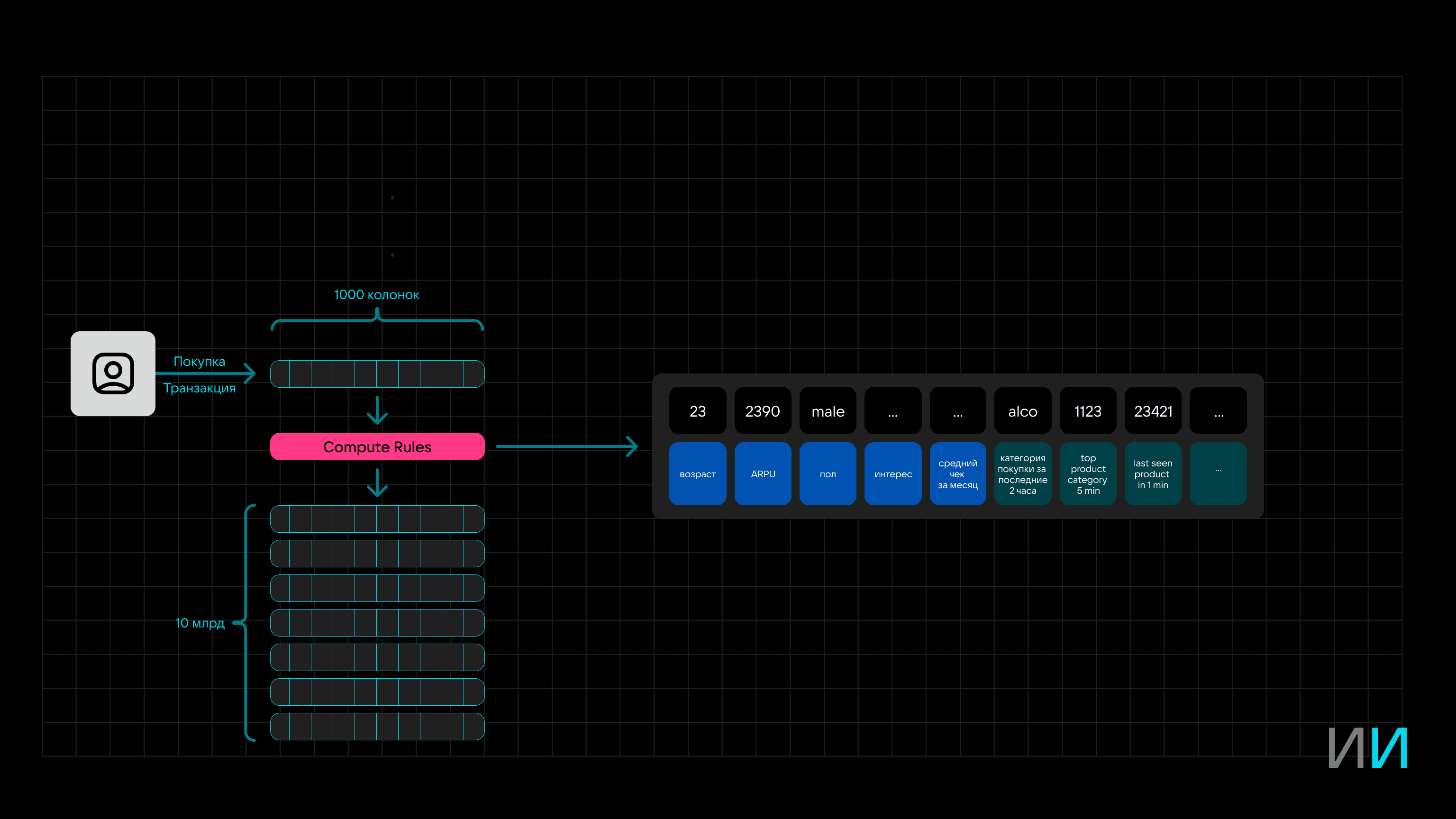
На основе этих фичей можно сформировать граф пользователя, а при обработке с помощью нейросети можно получить Search Vector для конкретного человека.
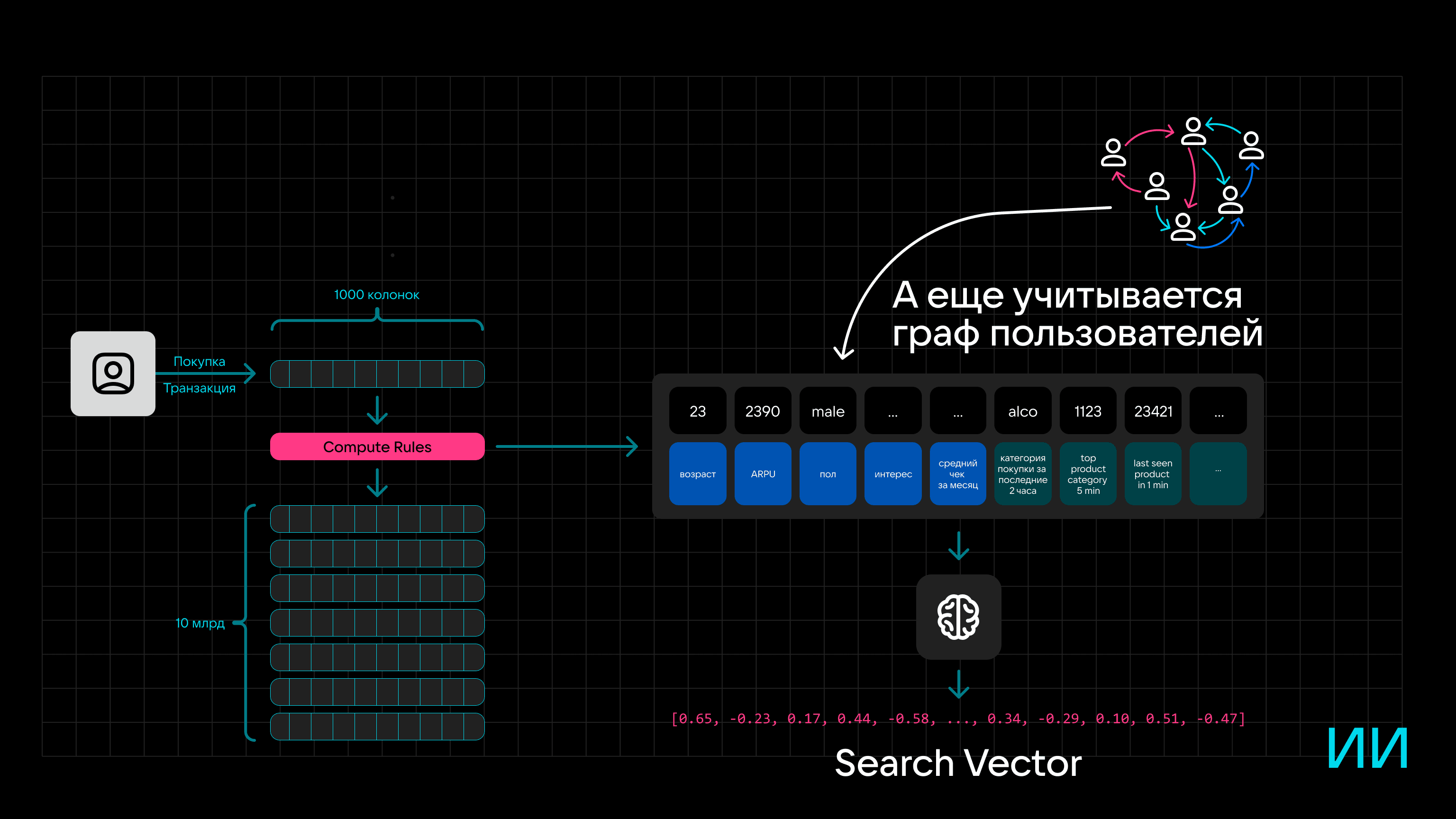
Если добавить в схему векторный движок и хранилище эмбеддингов, систему можно использовать не только для определения предпочтений пользователя (для этого и нужен граф), но и для выявления подозрительной активности, если параметры счетчиков указывают на фрод.
Вместо Hadoop для хранения транзакций, фичей и других данных в такой вероятностной системе можно заюзать S3-хранилище. Причем Compute- и Storage-слои можно разделить «еще на берегу», чтобы обеспечить высокую производительность и получить возможность независимого масштабирования.
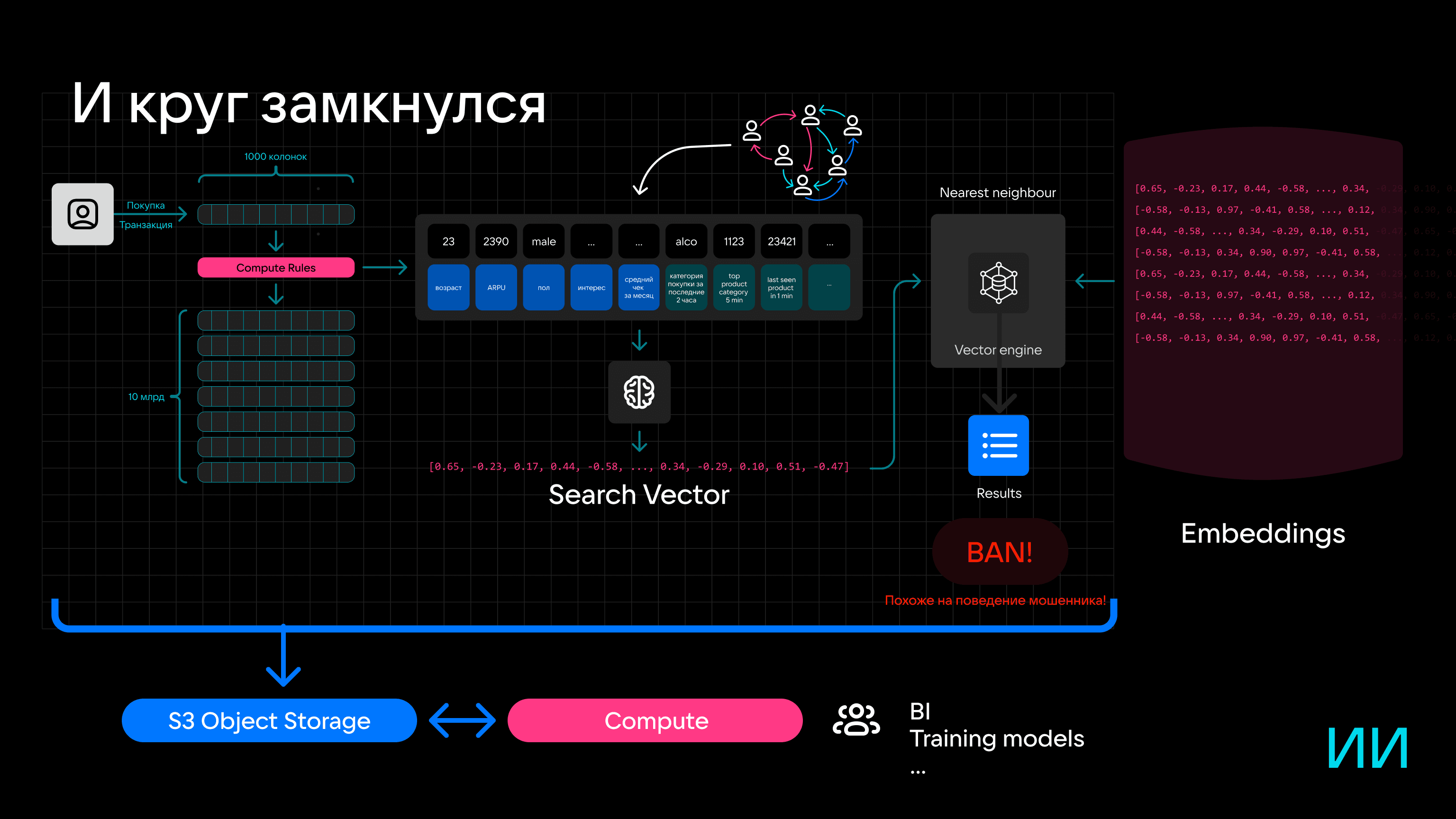
Подведем итоги
В условиях высокой конкуренции побеждает тот, кто способен решать задачи быстрее, производительнее и точнее конкурентов. Это повышает требования к разработчикам и делает самыми востребованными технологии и решения, которые рвут шаблоны: работа с нейросетями и векторными движками, комбинирование OLAP и OLTP в HTAP, использование S3 для быстрой аналитики, разделение Compute- и Storage-слоев. Примечательно, что инструменты для реализации таких сценариев не «что-то космическое», а уже есть. В том числе они есть в пакете VK Tech: In-memory-колоночная СУБД Tarantool Column Store, Tarantool DB, Tarantool Graph DB, S3-хранилище.
Остались вопросы?
Расскажите о ваших задачах и узнайте больше
о реализации на платформе Tarantool
Читайте также

Что такое Tarantool 3.0 и почему он стал удобнее для пользователей

Как правильно приготовить «данные»? Тренды разработки 2023

Графовые базы данных: определение, принципы, применение

Строим кэши и витрины данных с Tarantool DB
